Project Guide
Py4Stats の設計指針
Py4Stats ライブラリでは、次のような設計方針で開発を進めています。
- Python を用いたデータ分析の初心者から中級者をユーザー層として想定する
- ユーザーが分析ワークフローの大きな変更を強いられることなく利用できること
- Python や統計学に関する高度な知識を要求しないこと
- 必要最小限のコードで使用できること
上記の設計方針を実現するために、次のような取り組みを行なっています。
- To do with Py4Stats
- 探索的データ分析および回帰分析の結果レポートティングを円滑化・簡略化するためのユーティリティを提供する
- 基本的には1つの関数で完結する処理を実装する
- ユーザーフレンドリーな UI を重視する
- ドキュメントを充実させる
- 不適切な入力でエラーが生じた場合、その理由や適切な値の候補を提示すること
- docstring や API ドキュメントページでは、機能面の説明に加えてすぐにコピーして使える使用例を提示する
- Not do with Py4Stats
- 既存の Python ライブラリで良い実装が提供されている機能は実装しない
Py4Stats ライブラリのモジュール構成
2026年2月21日時点で、Py4Stats ライブラリのモジュールは次のように構成されています。
py4stats
├ メインモジュール # Import py4stats で直接読み込み
│ ├ eda_tools # 探索的データ解析と前処理
│ │ ├ _utils # eda_tools 用の型変換とアサート関数
│ │ ├ operation # 前処理と記述統計
│ │ ├ visualize # 可視化関数
│ │ ├ reviewing # 前処理のレビュー
│ │ └ _.pandas # Pandas ベースの旧実装(廃止予定)
│ └ regression_tools # 回帰分析の可視化と表作成
└ サブモジュール # Import py4stats では読み込まれない
├ heckit_helper #regression_tools の追加メソッド
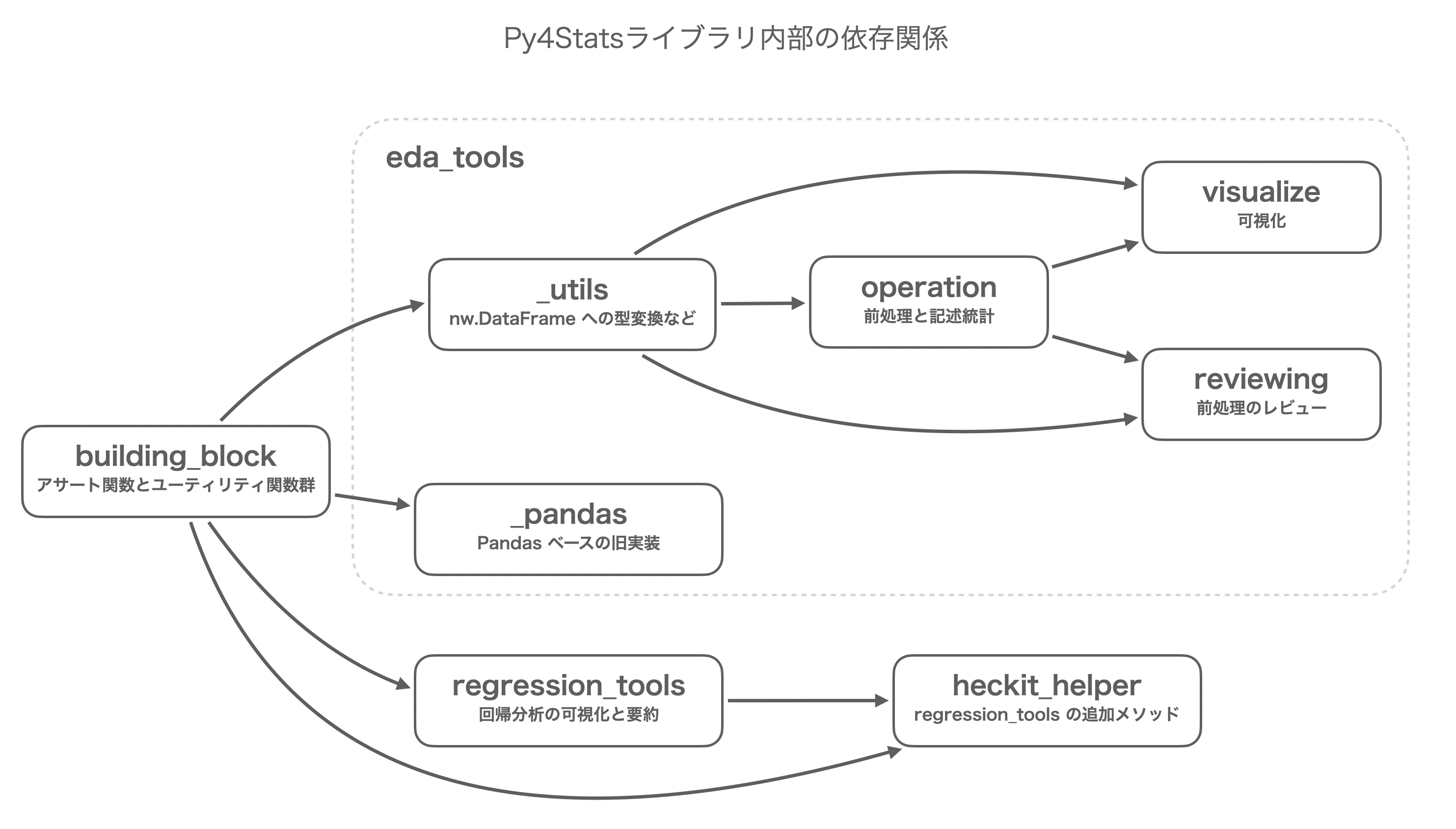
└ building_block # 内部実装用のアサーション関数とユーティリティ関数を提供また、各モジュールの実装は次の図のような依存関係を持っています。 このように building_block モジュールは eda_tools や regression_tools を実装する上での基盤という位置付けとなっています。Py4Stats ライブラリの実装においては、逆方向の依存関係を発生させないことを前提としています。
Py4Stats ライブラリのインポート
# ライブラリの読み込み(推奨)
import py4stats as py4st
# モジュール単位の読み込み
from py4stats import eda_tools as eda
from py4stats import regression_tools as reg
from py4stats import heckit_helper
from py4stats import building_block as build
# eda_tools のサブモジュールの読み込み
from py4stats.eda_tools import operation as eda_ops
from py4stats.eda_tools import visualize as eda_vis
from py4stats.eda_tools import reviewing as eda_review
# eda_tools のバックエンド別実装の明示的な読み込み(将来的に変更の可能性あり)
from py4stats.eda_tools import _nw as eda_nw
from py4stats.eda_tools import _pandas as eda_pdリポジトリのディレクトリ構成
2026年2月21日現在、Py4Stats リポジトリのディレクトリは、次のように構成されています。
Py4Stats
├── README.md # GitHub リポジトリのトップページ用ファイル
├── index.qmd # APIドキュメント(Quarto Book)のトップページ
├── _quarto.yml # Quarto Book の設定ファイル
├── introduction.qmd
├── articles # APIドキュメント以外の公開記事
├── man # APIドキュメントのうち、関数のドキュメント
│ ├── diagnose.qmd
│ ├── compare_ols.qmd
│ ...
│ └── image # ドキュメントに使用する画像
├── py4stats
│ ├── __init__.py # Py4Stats の Import 時に読み込まれる関数を定義
│ ├── building_block.py # 引数のアサーションなどユーティリティモジュール
│ ├── eda_tools # 探索的データ解析
│ │ ├── __init__.py
│ │ ├── _utils.py # eda_tools 用の型変換とアサート関数
│ │ ├── operation.py # 前処理と記述統計
│ │ ├── visualize.py # 可視化関数
│ │ ├── reviewing.py # 前処理のレビュー
│ │ ├── _nw.py # 後方互換性のための読み込み窓口
│ │ └── _pandas.py # バックエンドに pandas を使用した旧仕様
│ ├── heckit_helper.py
│ └── regression_tools.py # 回帰分析の可視化と作表
├── pyproject.toml
├── reference.md # man/ の関数ドキュメントへのリンク集
├── setup.ipynb
├── setup.py
└── tests # APIのテストコード
├── fixtures # 自動テストで参照するデータ
├── test_building_block.py
├── eda_tools
│ ├── setup_test_function.py # テストを円滑化するための関数を定義
│ ├── _utils.py
│ ├── operation.py
│ ├── visualize.py
│ └── reviewing.py
├── test_eda_tools_pandas.py
├── test_heckit_helper.py
└── test_regression_tools.py注意:eda_tools._pandas.py は 非推奨扱いで将来的に廃止する予定です。詳細は以下を参照してください。
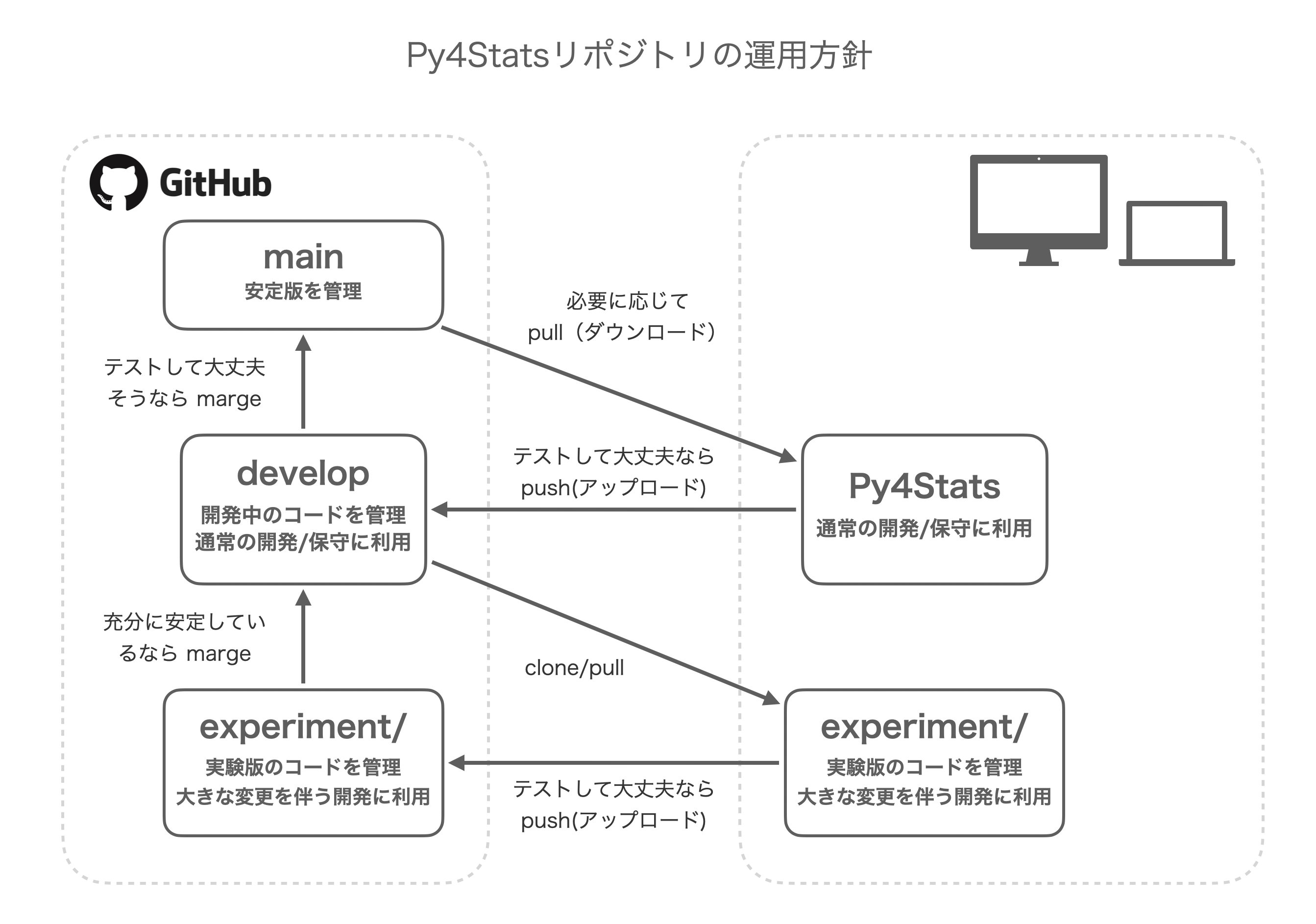
リポジトリの運用方針
セマンティック バージョニングについてのメモ
Py4Stats ライブラリのバージョンは次の方式のセマンティック バージョニングで管理します(e.g. v 0.1.0)。
v MAJOR.MINOR.PATCHv MAJOR.MINOR.PATCH の各要素は、次の規則で更新します。
MAJORAPIの変更に互換性のない場合はメジャーバージョンを上げるMINOR後方互換性があり機能性を追加した場合はマイナーバージョンを上げるPATCH後方互換性を伴うバグ修正をした場合はパッチバージョンを上げる
デザインパターン
引数のアサーション
from py4stats import building_block as build
# 文字列引数のアサーション(選択肢を制限)
arg = build.arg_match(
arg, values = ['option_1', 'option_2'],
arg_name = 'arg',
)build.assert_logical(arg, arg_name = 'arg') # ブール値
build.assert_character(arg, arg_name = 'arg') # 文字列
build.assert_numeric(arg, arg_name = 'arg') # 数値(int or float)
build.assert_integer(arg, arg_name = 'arg') # 整数値(int)
build.assert_count(arg, arg_name = 'arg') # 非負整数値(int)
build.assert_float(arg, arg_name = 'arg') # フロート値(float)narwhals が受け入れ可能な互換オブジェクトに singledispatch する方法
結論
- DataFrame の場合
@foo.register(nw.typing.IntoDataFrame)を使う - Series の場合
@foo.register(nw.typing.IntoSeries)を使う
詳細
functools.singledispatch を使って総称関数を定義する場合、@singledispatch デコレータで総称関数を定義したあと、@foo.register(Class) デコレータでクラス毎のメソッド関数を定義します。
narwhals が受け入れ可能な DataFrame 互換オブジェクトに対するメソッドを定義する場合には、nw.typing.IntoDataFrame を使い、Series 互換オブジェクトに対するメソッドを定義する場合には nw.typing.IntoSeries を使います。
# 実装例
import narwhals as nw
from functools import singledispatch
@singledispatch
def foo(x):
return 'I am some object'
@foo.register(nw.typing.IntoDataFrame)
def foo_df(x):
return 'I am a DataFrame'
@foo.register(nw.typing.IntoSeries)
def foo_s(x):
return 'I am a Series'# 動作例
import pandas as pd
import polars as pl
import pyarrow as pa
data_pd = pd.DataFrame({'x':[1, 2, 3], 'y':['a', 'b', 'c']})
data_pl = pl.from_pandas(data_pd)
data_pa = pa.Table.from_pandas(data_pd)
data_nw = nw.from_native(data_pd)
data_dict = {
'df_pd' :data_pd, 'df_pl' :data_pl, 'df_pa' :data_pa, 'df_nw' :data_nw,
's_pd' :data_pd['x'], 's_pl' :data_pl['x'], 's_pa' :data_pa['x'], 's_nw':data_nw['x'],
'int': 1
}
[f"{k}: {foo(x)}" for k, x in zip(data_dict.keys(), data_dict.values())]
#> ["df_pd: 'I am a DataFrame'",
#> "df_pl: 'I am a DataFrame'",
#> "df_pa: 'I am a DataFrame'",
#> "df_nw: 'I am a DataFrame'",
#> "s_pd: 'I am a Series'",
#> "s_pl: 'I am a Series'",
#> "s_pa: 'I am a Series'",
#> "s_nw: 'I am a Series'",
#> "int: 'I am some object'"]総称関数の実装に関する覚書
総称関数に登録されたメソッドの確認
結論
- ある関数に登録されたメソッド全体を確認するには
foo.registryを使い - ある関数に登録された特定のクラスのメソッドを確認するには
foo.dispatch(Class)を使います
詳細
ある総称関数に、どのようなメソッドが登録されているかは、.registry 属性で確認することができます。.registry は {型: 実装関数} の辞書であり、object クラスはデフォルト実装に対応しています。
import py4stats as py4st
import pandas as pd
registry = py4st.is_dummy.registry
print(pd.Series(registry).apply(lambda x: x.__name__))
#> <class 'object'> is_dummy
#> <class 'narwhals._native.NativeSeries'> is_dummy_series
#> <class 'narwhals.series.Series'> is_dummy_series
#> <class 'narwhals._native.NativeDataFrame'> is_dummy_data_frame
#> <class 'narwhals.dataframe.DataFrame'> is_dummy_data_frame
#> <class 'tuple'> is_dummy_list
#> <class 'list'> is_dummy_list
#> dtype: objectまた、.dispatch(Class) メソッドで特定のオブジェクトクラスに対して実装されたメソッド関数を確認することができます。
print(py4st.is_dummy.dispatch(pd.DataFrame).__name__)
#> is_dummy_data_frame
print(py4st.is_dummy.dispatch(pd.Series).__name__)
#> is_dummy_series
print(py4st.is_dummy.dispatch(list).__name__)
#> is_dummy_list
print(py4st.is_dummy.dispatch(int).__name__) # デフォルト実装
#> is_dummy関数ドキュメントでのバックエンド対応状況の表示
それぞれの関数に対するテストの実施状況は、shields.io で作成し Static Badge を使って表示します。
Pandas, Polars, Pyarrow の全てについてテストを実施して動作が確認できている場合、ドキュメントの冒頭に次のバッジを追加します。
![]()
[{fig-align="left" fig-alt="badge of tested backend"}](../articles/eda_tools_development_status.qmd)一方で、動作が確認できているバックエンドが Pandas のみで、Polars, Pyarrow ではテストできていない場合には、次のバッジを使用します。
![]()
![]()
[{fig-align="left" fig-alt="badge of tested backend"}](../articles/eda_tools_development_status.qmd)
[{fig-align="left" fig-alt="badge of not tested backend"}](../articles/eda_tools_development_status.qmd)このように、Pandas, Polars, Pyarrow の全てで動作が確認できていない場合には、バッジの色を変えることで位置付けを明示します。
注意点
上記のバッジの意味・用途については、あくまでテストで動くことを確認済みであることを示すものとします。テストを実施した上でも、特定のバックエンドでは機能の制限や既知のエラーがある場合には、ドキュメントや docstring の Notes セクションに明記することとします。
関数ライフサイクルの表示
本ライブラリにおける関数のライフサイクルは、R の lifecycle パッケージを参考に、次のようなバッジで表示します。
![]()
![]()
![]()
![]()
ライフサイクルにおける各ステージの意味は次の通りです。
| ステージ | 意味 | エラー/警告 | 維持方針 |
|---|---|---|---|
| experimental | 仕様が変わる可能性あり | なし | 破壊的変更あり得る |
| stable | 安定した仕様 | なし | 維持・非破壊的 |
| superseded | 代替あり・削除予定なし | なし | 互換維持 |
| deprecated | 代替あり・削除予定 | 警告あり | 移行を促進 |
特別な事情がなければ stable をデフォルトとして、その場合にはバッジを省略する形にしたいと思います。
なお、それぞれのバッジを表示する markdown のコードは次の通りです。
![]()
{fig-align="left" fig-alt="badge of lifecycle experimental"}![]()
{fig-align="left" fig-alt="badge of lifecycle stable"}![]()
{fig-align="left" fig-alt="badge of lifecycle supreseded"}![]()
{fig-align="left" fig-alt="badge of lifecycle deprecated"}